
반응형
김희성의 개발자 면접 cs 강의/ 스터디
자료형
- 변수란?
- 값을 저장할 때 사용하는 식별자
- 값의 이름과 저장위치의 쌍
- 저장위치 = 메모리
- 즉 변수는 값을 저장한 메모리 주소에 대응.
| 자료형 | 표현 범위 | 메모리 | 연산 속도 |
| int | -2,147,483,648 ~ 2,147,483,647 | 32bit( =4Byte) | 가장 빠름 |
| Long(int64) | -9223372036854775808 ~ +9223372036854775807 |
64bit( =8Byte) | int 대비 느림 |
| float | 정확도 낮음(유효자리수:7) | 32bit( =4Byte) | int 대비 느림 |
| double | 정확도 높음(유효자리수:16) | 64bit( =8Byte) | int 대비 느림 |
* 위 자료형 중 대부분 CPU에서는 int 형이 연산속도가 가장 빠르다.
시간/공간 복잡도
- 시간 복잡도 : 로직(코드)의 수행 시간이 얼마나 소요되는지를 대략적으로 표현하는 것
- 코드의 수행 시간은 코드의 길이나 양이 아니라 시간 복잡도에 더 큰 연관이 있다. (시간과 무조건 비례하진않는다)
- 공간 복잡도 : 로직(코드)의 수행에 얼마나 많은 메모리를 필요로 하는지 대략적으로 표현하는 것
- 어떤 자료형을 얼만큼 메모리에 저장하느냐 에 따라 대략적으로 계산이 가능하다. (변수의 양)
(*코딩테스트는 싱글스레드로 멀티스레드함수 쓰면 속도에 문제 생길 수 있음.)
Sorting(정렬)

- 삽입정렬 : 정렬되어 있는 배열에 새로운 값의 위치를 찾아서 삽입하는 정렬 방식
- Insertion Sort 는 초기 배열이 어느정도 정렬되어 있는지에 따라 성능이 달라진다.
- 정렬이 어느정도 되어 있다면 성능이 좋다.
- 그림의 예시처럼 완전히 정렬 되어 있다면, O(N)에 동작한다.
- 반대로 역순 정렬되어 있었다 면, 삽입 정렬의 로직상 Worst 케이스인 O(N^2)이 된다.
- 퀵 정렬
- Pivot 을 선택하는 로직을 다르게 하는 등 다양한 방법으로 개 선한 Quick Sort 가 있지만, Worst Case 에서 O(N^2)임은 변함 이 없다.
- 비록 Worst Case 에서는 O(N^2)의 시간 복잡도를 갖지만 대부 분의 자연적인(Random) 데이터에서는 O(NlogN)의 성능을 보 여주며, 다른 O(NlogN)의 정렬 알고리즘들 보다 빠르게 동작 한다.
- 자연적인(Random) 데이터의 Case에서는 Pivot 기준으로 ½ 근사 값으로 나누어질 가능성이 높다.
- 시간 복잡도는 O(N * logN)이 된다
- 병합정렬
- 정렬된 두 개의 배열을 합치면서 정렬하는 연산은 O(N) 이다.
- Merge * H = O(N) * O(logN) = O(NlogN)

- Counting Sort
- 시간 복잡도 : O(N) + O(M) (N = 데이터 수, M = 데이터의 범위 1 ~ M)
- 공간 복잡도 : O(M) (M = 데이터의 범위 1 ~ M)
- 따라서 데이터의 범위가 넓을수록 성능(시간, 공간)이 좋지 않다
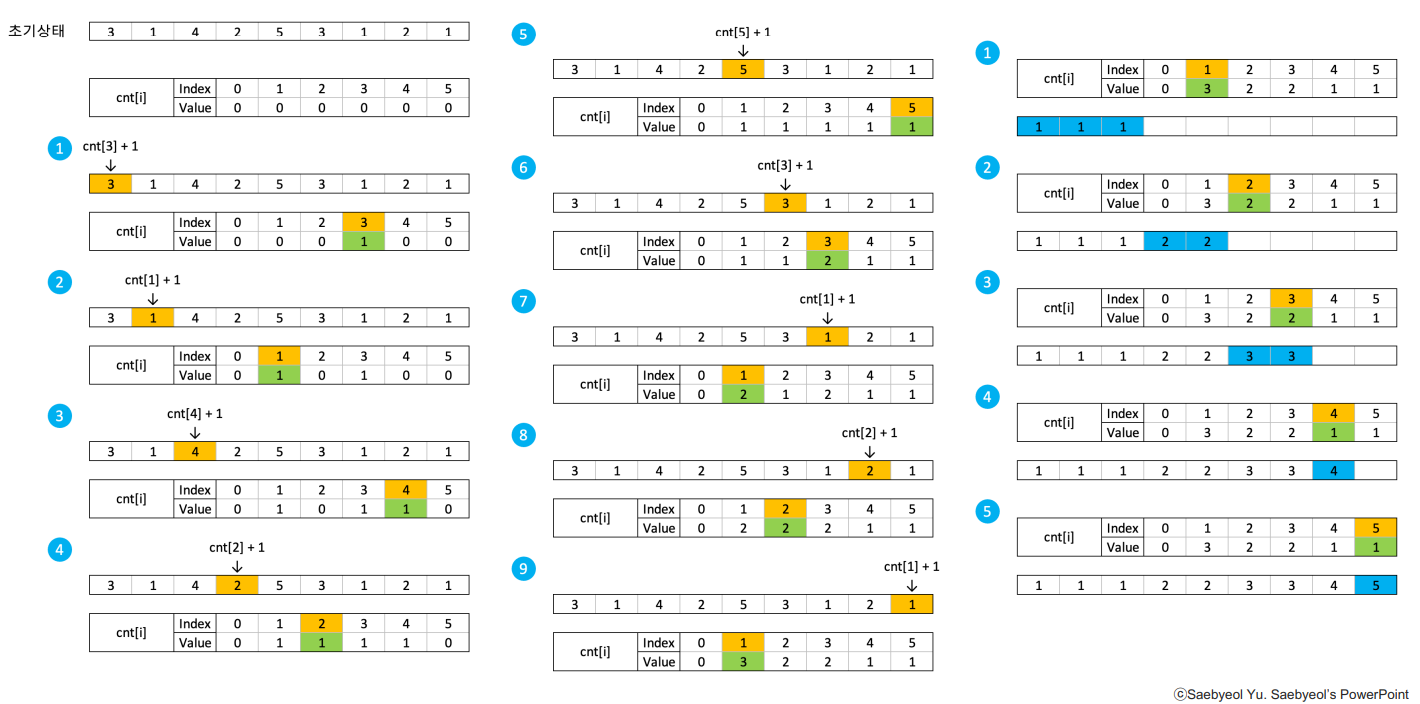
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] arr= new int[]{1, 5, 2, 3, 5, 4, 2, 3};
int[] cnt= new int[6];
for(int i : arr){
cnt[i]++;
}
System.out.println(Arrays.toString(cnt)); //value 값 출력
for (int i=1; i<cnt.length; i++){ //입력 값의 범위 O(M) +
for (int j = 0; j < cnt[i]; j++) { //입력 데이터의 개수 O(N)
System.out.print(i + " "); //index 출력
}
}
}
}
마지막 for문을 보면 이중for문은 O(M)과 O(N) 사이가 더하기로 연결된다.
Binary Search (이진 탐색)
- 정렬되어 있는 데이터 사이에서 특정 데이터를 찾을 때, O(logN) 의 시간 복잡도로 찾는 알고리즘
- 배열이 정렬되어 있지 않다면 이진 탐색을 사용할 수 없다.
- 대부분의 언어에서 표준 API 로 제공하지만, Parametric Search 알고리즘을 구현하기 위해서라 도 직접 구현하는 것을 연습해두면 좋다.
- 소주병 숫자맞추기 게임생각하면 좋다!
반응형
'Backend > CS' 카테고리의 다른 글
| [자료구조] HashTable (HashMap, unordered_map(set)) - 2 (0) | 2024.03.14 |
|---|---|
| [자료구조] Priority Queue (0) | 2024.03.13 |
| [자료구조] HashTable (HashMap, unordered_map(set)) (0) | 2024.02.23 |
| [자료구조] Queue, Deque, Stack (0) | 2024.02.22 |
| [자료구조] Array, ArrayList (0) | 2024.02.21 |